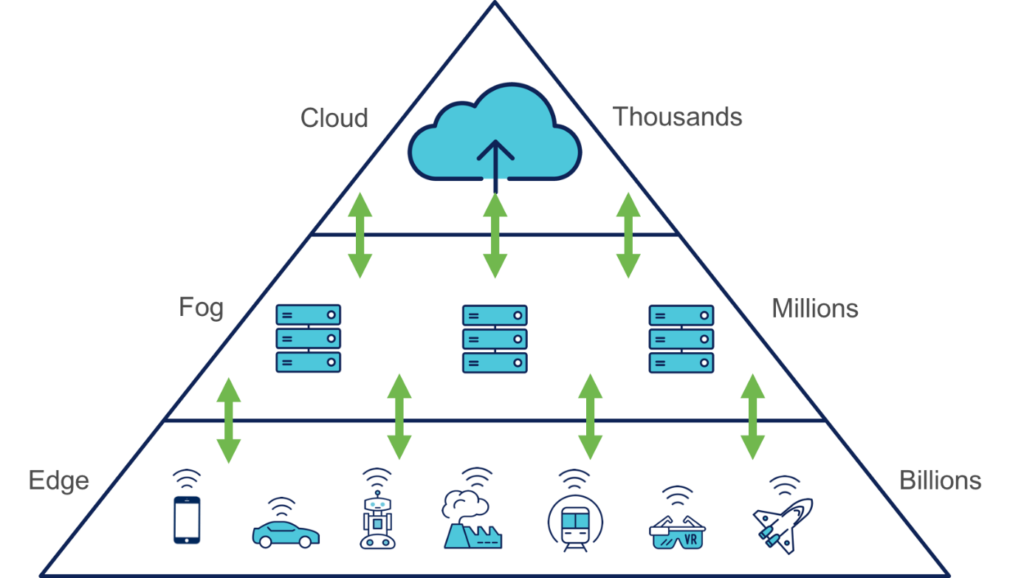
Nous commençons à tous entendre parler de Cloud, Flog et Edge Computing. Ce sont des terminologies de plus en plus répandues mais encore souvent méconnues. Elles constituent des couches de l’architecture IIoT (Internet Industriel des Objets) où chacune possède des caractéristiques et des usages propres et où tous trouvent une certaine complémentarité.
Depuis l’avènement de l’Internet Industriel des Objets…
Avec l’avènement de l’IIoT, l’augmentation des données à traiter (Big Data) provenant des couches basses de l’automation (capteurs de température, vibration, détection, E/S, Machine vision, IA, machine learning…) est exponentielle, c’est précisément ce qui induit à une réorganisation vers une infrastructure plus appropriée.
Cloud compluting (l’informatique dans les nuages)
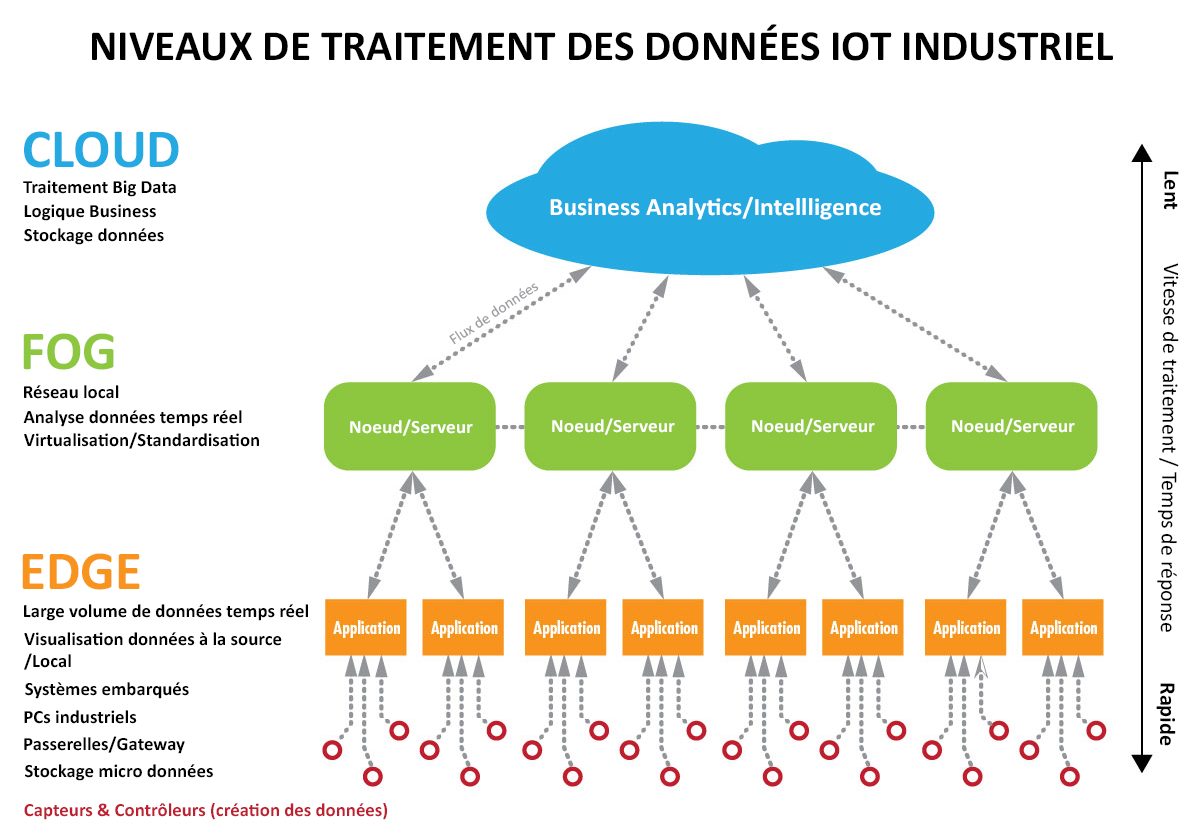
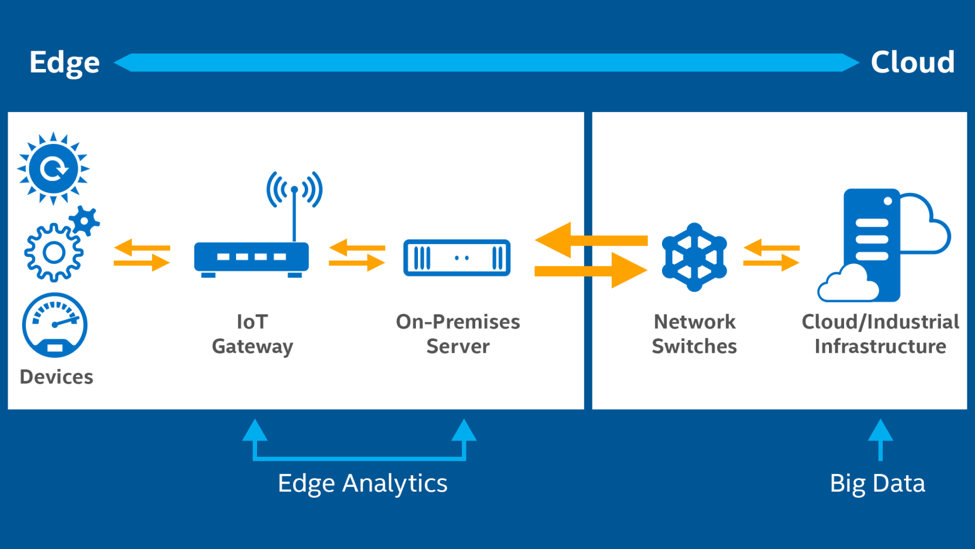
Une architecture centralisée (Cloud ou serveurs locaux) a l’avantage d’exploiter au maximum les capacités de calcul des machines virtuelles ou physiques distantes pour fournir à l’utilisateur final de nouveaux services (flexibilité, haute disponibilité, optimisation des coûts de possession…). Toutefois, le flux de données à traiter est tel qu’il congestionnerait rapidement les infrastructures réseaux, cette latence impacterait alors fortement les moyens de production. Cette couche se concentre essentiellement sur le Big Data, le Data analysis et le machine learning.

Fog Computing (l’informatique dans le brouillard) et Edge Computing (l’informatique de bord ou embarquée)
Considérés comme une extension du Cloud Computing, ils sont physiquement situés sur le réseau d’entreprise et sont le relais entre les équipements couche basse OT et la couche haute IT. Ils libèrent de la bande passante et garantissent un traitement local des applications de production et tout cela en temps réel.
Les données critiques étant traitées localement, leurs intégrités sont préservées et la notion de cybersécurité est ainsi bien présente et maîtrisée. Le Fog computing est principalement assimilé à des passerelles de communications industrielles de terrain vers des protocoles IoT alors que le Edge computing est directement lié aux moyens de production et autres capteurs où le traitement applicatif et calculs sont effectués. Le facteur de forme de ces calculateurs est souvent le plus minimaliste possible pour ainsi être facilement intégrable. Découvrir une gamme de produits Edge Computing >
Cas concret : la voiture autonome
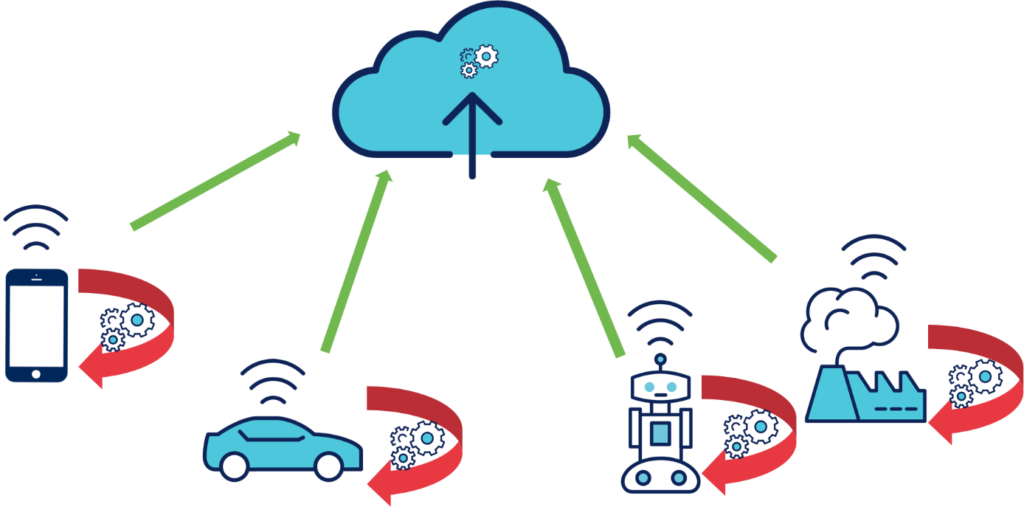 Intel estime qu’un véhicule autonome doté de centaines de capteurs, générera près de 40 Tb de données en l’espace de 8 heures de conduite. Une quantité de données difficilement transmissible avec les moyens de communications actuels et potentiellement exposée à des cyber-attaques.
Intel estime qu’un véhicule autonome doté de centaines de capteurs, générera près de 40 Tb de données en l’espace de 8 heures de conduite. Une quantité de données difficilement transmissible avec les moyens de communications actuels et potentiellement exposée à des cyber-attaques.
D’autre part, pour des questions de sécurités évidentes, certaines actions nécessitent une prise de décision en temps réel où aucun temps de latence n’est acceptable. L’Edge computing est alors une solution qui assure le traitement local des données et détermine seul les actions qui en résultent.
En revanche, l’analyse complète des données d’un parc de véhicules autonomes ne nécessitant pas une prise de décision immédiate (autonomie, parcours, maintenance préventive…) peut être mis à disposition du Cloud computing. Les données sont ainsi analysées dans leur globalité et offrent de nouveaux usages et améliorent l’expérience utilisateur.